 | CGI Programming with Perl |  |

Communicating with Other Servers
An Introduction to XML
Document Type Definition
Writing an XML Parser
CGI Gateway to XML Middleware
CGI programming has been used to make individual web applications from simple guestbooks to complex programs such as a calendar capable of managing the schedules of large groups. Traditionally, these programs have been limited to displaying data and receiving input directly from users.
However, as with all popular technologies, CGI is being pushed beyond these traditional uses. Going beyond CGI applications that interact with users, the focus of this chapter is on how CGI can be a powerful means of communicating with other programs.
We have seen how CGI programs can act as a gateway to a variety of resources such as databases, email, and a host of other protocols and programs. However, a CGI program can also perform some sophisticated processing on the data it gets so that it effectively becomes a data resource itself. This is the definition of CGI middleware. In this context, the CGI application sits between the program it is serving data to and the resources that it is interacting with.
The variety of search engines that exist provides a good example of why CGI middleware can be useful. In the early history of the Web, there were only a few search engines to choose from. Now, there are many. The results these engines produce are usually not identical. Finding out about a rare topic is not an easy task if you have to jump from engine to engine to retry the search.
Instead of trying multiple queries, you would probably rather issue one query and get back results from many search engines in a consolidated form with duplicate responses already filtered out. To make this a reality, the search engines themselves must become CGI middleware engines, talking to one CGI script that consolidates the results.
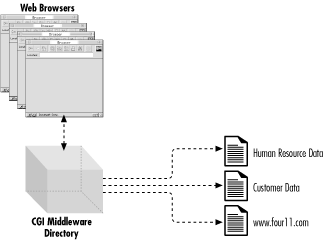
Furthermore, a CGI middleware layer can be used to consolidate databases other than ones on the Internet. For example, a company-wide directory service could be programmed to search several internal phone directory databases such as customer data and human resources data as well as using an Internet phone resource such as http://www.four11.com/ if the information is lacking internally, as shown in Figure 14-1.
Two technologies to illustrate the use of CGI middleware will be demonstrated later in this chapter. First, we will look at how to perform network connections from your CGI scripts in order to talk to other servers. Then, we introduce eXtensible Markup Language (XML), a platform-independent way of transferring data between programs. We'll show an example using Perl's XML parser.
Let's look at the typical communication scheme between a client and a server. Consider an electronic mail application, for example. Most email applications save the user's messages in a particular file, typically in the /var/spool/mail directory. When you send mail to someone on a different host, the mail application must find the recipient's mail file on that server and append your message to it. How does the mail program achieve this task, since it cannot manipulate files on a remote host directly?
The answer to this question is interprocess communication (IPC). Typically, there exists a process on the remote host, which acts as a messenger for dealing with email services. When you send a message, the local process on your host communicates with this remote agent across a network to deliver mail. As a result, the remote process is called a server (because it services an issued request), and the local process is referred to as a client. The Web works along the same philosophy: the browser represents the client that issues a request to an HTTP server that interprets and executes the request.
The most important thing to remember here is that the client and the server must speak the same language. In other words, a particular client is designed to work with a specific server. So, for example, an email client, such as Eudora, cannot communicate with a web server. But if you know the stream of data expected by a server, and the output it produces, you can write an application that communicates with the server, as you will see later in this chapter.
Most companies have a telephone switchboard that acts as a gateway for calls coming in and going out. A socket can be likened to a telephone switchboard. If you want to connect to a remote host, you need to first create a socket through which the communications would occur. This is similar to dialing "9" to go through the company switchboard to the outside world.
Similarly, if you want to create a server that accepts connections from remote (or local) hosts, you need to set up a socket that listens for connections. The socket is identified on the Internet by the host's IP address and the port that it listens on. Once a connection is established, a new socket is created to handle this connection, so that the original socket can go back and listen for more connections. The telephone switchboard works in the same manner: as it handles outside phone calls, it routes them to the appropriate extension and goes back to accept more calls.
For the sake of discussion, think of a socket simply as a pipe between two locations. You can send and receive information through that pipe. This concept will make it easier for you to understand socket I/O.
The IO::Socket module, which is included with the standard Perl distribution, makes socket programming simple. Example 14-1 provides a short program that takes a URL from the user, requests the resource via a GET method, then prints the headers and content.
#!/usr/bin/perl -wT
use strict;
use IO::Socket;
use URI;
my $location = shift || die "Usage: $0 URL\n";
my $url = new URI( $location );
my $host = $url->host;
my $port = $url->port || 80;
my $path = $url->path || "/";
my $socket = new IO::Socket::INET (PeerAddr => $host,
PeerPort => $port,
Proto => 'tcp')
or die "Cannot connect to the server.\n";
$socket->autoflush (1);
print $socket "GET $path HTTP/1.1\n",
"Host: $host\n\n";
print while (<$socket>);
$socket->close;We use the URI module discussed in Chapter 2, "The Hypertext Transport Protocol ", to break the URL supplied by the user into components. Then we create a new instance of the IO::Socket::INET object and pass it the host, port number, and the communications protocol. And the module takes care of the rest of the details.
We make the socket unbuffered by using the autoflush method. Notice in the next set of code that we can use the instance variable $socket as a file handle as well. This means that we can read from and write to the socket through this variable.
This is a relatively simple program, but there is an even easier way to retrieve web resources from Perl: LWP.
LWP , which stands for libwww-perl, is an implementation of the W3C's libwww package for Perl by Gisle Aas and Martijn Koster, with contributions from a host of others. LWP allows you to create a fully configurable web client in Perl. You can see an example of some of what LWP can do in Section 8.2.5, "Trusting the Browser".
With LWP, we can write our web agent as shown in Example 14-2.
#!/usr/bin/perl -wT
use strict;
use LWP::UserAgent;
use HTTP::Request;
my $location = shift || die "Usage: $0 URL\n";
my $agent = new LWP::UserAgent;
my $req = new HTTP::Request GET => $location;
$req->header('Accept' => 'text/html');
my $result = $agent->request( $req );
print $result->headers_as_string,
$result->content;Here we create a user agent object as well as an HTTP request object. We ask the user agent to fetch the result of the HTTP request and then print out the headers and content of this response.
Finally, let's look at LWP::Simple. LWP::Simple does not offer the same flexibility as the full LWP module, but it is much easier to use. In fact, we can rewrite our previous example to be even shorter; see Example 14-3.
#!/usr/bin/perl -wT use strict; use LWP::Simple; my $location = shift || die "Usage: $0 URL\n"; getprint( $location );
There is a slight difference between this and the previous example. It does not print the HTTP headers, just the content. If we want to access the headers, we would need to use the full LWP module instead.
|  | |
| 13.5. PerlMagick |  | 14.2. An Introduction to XML |

Copyright © 2001 O'Reilly & Associates. All rights reserved.