 | CGI Programming with Perl |  |

The following CGI script will act as a gateway parsing the XML from the Netscape What's Related server. Given a URL, it will print out all the related URLs. In addition, it will also query the Netscape What's Related server for all the URLs related to this list of URLs and display them. From this point onward, we will refer to URLs that are related to the first set of related URLs as second-level related URLs. Figure 14-2 shows the initial query screen while Figure 14-3 illustrates the results from a sample query. Example 14-4 shows the HTML for the initial form.

<HTML>
<HEAD>
<TITLE>What's Related To What's Related Query</TITLE>
</HEAD>
<BODY BGCOLOR="#ffffff">
<H1>Enter URL To Search:</H1>
<HR>
<FORM METHOD="POST">
<INPUT TYPE="text" NAME="url" SIZE=30><P>
<INPUT TYPE="submit" NAME="submit_query" VALUE="Submit Query">
</FORM>
</BODY>
</HTML>Two Perl modules will be used to provide the core data connection and translation services to the search engine. First, the library for web programming ( LWP) module will be used to grab data from the search engine. Since the What's Related server can respond to GET requests, we use the LWP::Simple subset of LWP rather than the full-blown API. Then, XML::Parser will take the retrieved data and process it so that we can manipulate the XML using Perl data structures. The code is shown in Example 14-5.
#!/usr/bin/perl -wT
use strict;
use constant WHATS_RELATED_URL => "http://www-rl.netscape.com/wtgn?";
use vars qw( @RECORDS $RELATED_RECORDS );
use CGI;
use CGI::Carp qw( fatalsToBrowser );
use XML::Parser;
use LWP::Simple;
my $q = new CGI( );
if ( $q->param( "url" ) ) {
display_whats_related_to_whats_related( $q );
} else {
print $q->redirect( "/quiz.html" );
}
sub display_whats_related_to_whats_related {
my $q = shift;
my $url = $q->param( "url" );
my $scriptname = $q->script_name;
print $q->header( "text/html" ),
$q->start_html( "What's Related To What's Related Query" ),
$q->h1( "What's Related To What's Related Query" ),
$q->hr,
$q->start_ul;
my @related = get_whats_related_to_whats_related( $url );
foreach ( @related ) {
print $q->a( { -href => "$scriptname?url=$_->[0]" }, "[*]" ),
$q->a( { -href => "$_->[0]" }, $_->[1] );
my @subrelated = @{$_->[2]};
if ( @subrelated ) {
print $q->start_ul;
foreach ( @subrelated ) {
print $q->a( { -href => "$scriptname?url=$_->[0]" }, "[*]" ),
$q->a( { -href => "$_->[0]" }, $_->[1] );
}
print $q->end_ul;
} else {
print $q->p( "No Related Items Were Found" );
}
}
if ( ! @related ) {
print $q->p( "No Related Items Were Found. Sorry." );
}
print $q->end_ul,
$q->p( "[*] = Go to What's Related To That URL." ),
$q->hr,
$q->start_form( -method => "GET" ),
$q->p( "Enter Another URL To Search:",
$q->text_field( -name => "url", -size => 30 ),
$q->submit( -name => "submit_query", -value => "Submit Query" )
),
$q->end_form,
$q->end_html;
}
sub get_whats_related_to_whats_related {
my $url = shift;
my @related = get_whats_related( $url );
my $record;
foreach $record ( @related ) {
$record->[2] = [ get_whats_related( $record->[0] ) ];
}
return @related;
}
sub get_whats_related {
my $url = shift;
my $parser = new XML::Parser( Handlers => { Start => \&handle_start } );
my $data = get( WHATS_RELATED_URL . $url );
$data =~ s/&/&/g;
while ( $data =~ s|(=\"[^"]*)\"([^/ ])|$1'$2|g ) { };
while ( $data =~ s|(=\"[^"]*)<[^"]*>|$1|g ) { };
while ( $data =~ s|(=\"[^"]*)<|$1|g ) { };
while ( $data =~ s|(=\"[^"]*)>|$1|g ) { };
$data =~ s/[\x80-\xFF]//g;
local @RECORDS = ( );
local $RELATED_RECORDS = 1;
$parser->parse( $data );
sub handle_start {
my $expat = shift;
my $element = shift;
my %attributes = @_;
if ( $element eq "child" ) {
my $href = $attributes{"href"};
$href =~ s/http.*http(.*)/http$1/;
if ( $attributes{"name"} &&
$attributes{"name"} !~ /smart browsing/i &&
$RELATED_RECORDS ) {
if ( $attributes{"name"} =~ /no related/i ) {
$RELATED_RECORDS = 0;
} else {
my $fields = [ $href, $attributes{"name"} ];
push @RECORDS, $fields;
}
}
}
}
return @RECORDS;
}This script starts like most of our others, except we declare the @RECORDS and @RELATED_RECORDS as global variables that will be used to temporarily store information about parsing the XML document. In particular, @RECORDS will contain the URLs and titles of the related URLs, and $RELATED_RECORDS will be a flag that is set if related documents are discovered by Netscape's What's Related server. WHATS_RELATED_URL is a constant that contains the URL of Netscape's What's Related server.
In addition to the CGI.pm module, we use CGI::Carp with the fatalsToBrowser option in order to make any errors echo to the browser for easier debugging. This is important because XML::Parser dies when it encounters a parsing error. XML::Parser is the heart of the program. It will perform the data extraction of the related items. LWP::Simple is a simplified subset of LWP, a library of functions for grabbing data from a URL.
We create a CGI object and then check whether we received a url parameter. If so, then we process the query; otherwise, we simply forward the user to the HTML form. To process our query, a subroutine is called to display "What's Related to What's Related" to the URL (display_whats_related_to_whats_related ).
The display_whats_related_to_whats_related subroutine contains the code that displays the HTML of a list of URLs that are related to the submitted URL including the second-level related URLs.
We declare a lexical variable called @related. This data structure contains all the related URL information after the data gets returned from the get_whats_related_to_whats_related subroutine.
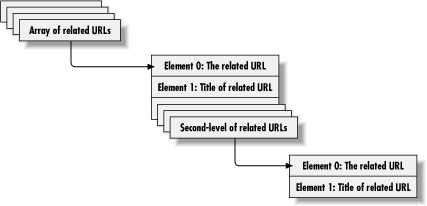
More specifically, @related contains references to the related URLs, which in turn contain references to second-level related URLs. @related contains references to arrays whose elements are the URL itself, the title of the URL, plus another array pointing to second-level related URLs. The subarray of second-level related URLs contains only two elements: the URL and the title. Figure 14-4 illustrates this data structure.
If there are no related items found at the top level submitted URL, a message is printed to notify the user.
Later, we want to print out self-referencing hypertext links back to this script. In preparation for this action, we create a variable called $scriptname that will hold the current scriptname for referencing in <A HREF> tags. CGI.pm's script_name method provides a convenient way of getting this data.
Of course, we could have simply chosen a static name for this script. However, it is generally considered good practice to code for flexibility where possible. In this case, we can name the script anything we want and the code here will not have to change.
For each related URL, we print out "[*]" embedded in an <A> tag that will contain a reference to the script itself plus the current URL being passed to it as a search parameter. If one element of @related contains ["http://www.eff.org/", "The Electronic Frontier Foundation"] the resulting HTML would look like this:
<A HREF="whatsrelated.cgi?url=http://www.eff.org/" >[*]</A> <A HREF="http://www.eff.org/">The Electronic Frontier Foundation</A>
This will let the user pursue the "What's Related" trail another step by running this script on the chosen URL. Immediately afterwards, the title ($_->[1]) is printed with a hypertext reference to the URL that the title represents ($_->[0]).
@subrelated contains the URLs that are related to the URL we just printed for the user ($_->[2]). If there are second-level related URLs, we can proceed to print them. The second-level related URL array follows the same format as the related URL array except that there is no third element containing further references to more related URLs. $_->[0] is the URL and $_->[1] is the title of the URL itself. If @subrelated is empty, the user is told that there are no related items to the URL that is currently being displayed.
Finally, we output the footer for the What's Related query results page. In addition, the user is presented with another text field in which they can enter in a new URL to search on.
The get_whats_related_to_whats_related subroutine contains logic to take a URL and construct a data structure that contains not only URLs that are related to the passed URL, but also the second-level related URLs. @related contains the list of what's related to the first URL.
Then, each record is examined in @related to see if there is anything related to that URL. If there is, the third element ($record->[2]) of the record is set to a reference to the second-level related URLs we are currently examining. Finally, the entire @related data structure is returned.
The get_whats_related subroutine returns an array of references to an array with two elements: a related URL and the title of that URL. The key to getting this information is to parse it from an XML document. $parser is the XML::Parser object that will be used to perform this task.
XML parsers do not simply parse data in a linear fashion. After all, XML itself is hierarchical in nature. There are two different ways that XML parsers can look at XML data.
One way is to have the XML parser take the entire document and simply return a tree of objects that represents the XML document hierarchy. Perl supports this concept via the XML::Grove module by Ken MacLeod. The second way to parse XML documents is using a SAX (Simple API for XML) style of parser. This type of parser is event-based and is the one that XML::Parser is based on.
The event based parser is popular because it starts returning data to the calling program as it parses the document. There is no need to wait until the whole document is parsed before getting a picture of how the XML elements are placed in the document. XML::Parser accepts a file handle or the text of an XML document and then goes through its structure looking for certain events. When a particular event is encountered, the parser calls the appropriate Perl subroutine to handle it on the fly.
For this program, we define a handler that looks for the start of any XML tag. This handler is declared as a reference to a subroutine called handle_start. The handle_start subroutine is declared further below within the local context of the subroutine we are discussing.
XML::Parser can handle more than just start tags. XML::Parser also supports the capability of writing handlers for other types of parsing events such as end tags, or even for specific tag names. However, in this program, we only need to declare a handler that will be triggered any time an XML start tag is encountered.
$data contains the raw XML code to be parsed. The get subroutine was previously imported by pulling the LWP::Simple module into the Perl script. When we pass WHATS_RELATED_URL along with the URL we are looking for to the get subroutine, get will go out on the Internet and retrieve the output from the "What's Related" web server.
You will notice that as soon as $data is collected, there is some additional manipulation done to it. XML::Parser will parse only well-formed XML documents. Unfortunately, the Netscape XML server sometimes returns data that is not entirely well-formed, so a generic XML parser has a little difficulty with it.
To get around this problem, we filter out potentially bad data inside of the tags. The regular expressions in the above code respectively transform ampersands, double-quotes, HTML tags, and stray < and > characters into well-formed counterparts. The last regular expression deals with filtering out non-ASCII characters.
Before parsing the data, we set the baseline global variables @RECORDS to the empty set and $RELATED_RECORDS to true (1).
Simply calling the parse method on the $parser object starts the parsing process. The $data variable that is passed to parse is the XML subject to be read. The parse method also accepts other types of data including file handles to XML files.
Recall that the handle_start subroutine was passed to the $parser object upon its creation. The handle_start subroutine that is declared within the get_whats_related subroutine is called by XML::Parser every time a start tag is encountered.
$expat is a reference to the XML::Parser object itself. $element is the start element name and %attributes is a hash table of attributes that were declared inside the XML element.
For this example, we are concerned only with tags that begin with the name "child" and contain the href attribute. In addition, the $href tag is filtered so any non-URL information is stripped out of the URL.
If there is no name attribute, or if the name attribute contains the phrase "Smart Browsing", or if there were no related records found previously for this URL, we do not want to add anything to the @RECORDS array. In addition, if the name attribute contains the phrase "no related", the $RELATED_RECORDS flag is set to false (0).
Otherwise, if these conditions are not met, we will add the URL to the @RECORDS array. This is done by making a reference to an array with two elements: the URL and the title of the URL. At the end of the subroutine, the compiled @RECORDS array is returned.
This program was a simple example of using a CGI program to pull data automatically from an XML-based server. While the What's Related server is just one XML server, it is conceivable that as XML grows, there will be more database engines on the Internet that deliver even more types of data. Since XML is the standard language for delivering data markup on the Web, extensions to this CGI script can be used to access those new data repositories.
More information about XML, DTD, RDF, and even the Perl XML::Parser library can be found at http://www.xml.com/. Of course, XML::Parser can also be found on CPAN.
|  | |
| 14.4. Writing an XML Parser |  | 15. Debugging CGI Applications |

Copyright © 2001 O'Reilly & Associates. All rights reserved.