

|
Preface |

|
To use Perl effectively in an application, you must be conversant with three aspects:
The Perl interpreter for writing C extensions for your Perl scripts or embedding the Perl interpreter in your C/C++ applications.
Technology issues such as networking, user interfaces, the Web, and persistence.
Figure 1 shows a map of the topics dealt with in this book. Each major aspect listed above is further classified. The rest of this section presents a small blurb about each topic and the corresponding chapter where the subject is detailed. The discussion is arranged by topic rather than by the sequence in which the chapters appear.
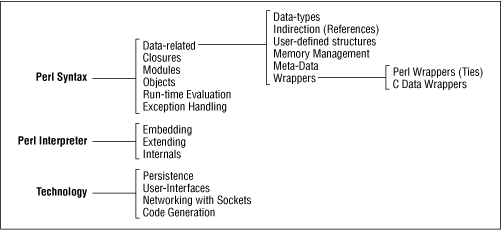
Pointers or references bring an enormous sophistication to the type of data structures you can create with a language. Perl's support for references and its ability to let you code without having to specify every single step makes it an especially powerful language. For example, you can create something as elaborate as an array of hashes of arrays[ 4 ] all in a single line. Chapter 1, Data References and Anonymous Storage , introduces you to references and what Perl does internally for memory management. Chapter 2, Implementing Complex Data Structures , exercises the syntax introduced in the earlier chapter with a few practical examples.
[4] We'll henceforth refer to indexed lists/arrays as "arrays" and associative arrays as "hashes" to avoid confusion.
Perl supports references to subroutines and a powerful construct called closures, which, as LISPers know, is essentially an unnamed subroutine that carries its environment around with it. This facility and its concomitant idioms will be clarified and put to good use in Chapter 4, Subroutine References and Closures .
References are only one way of obtaining indirection. Scalars can contain embedded pointers to native C data structures. This subject is covered in Chapter 20, Perl Internals . Ties represent an alternative case of indirection: All Perl values can optionally trigger specific Perl subroutines when they are created, accessed, or destroyed. This aspect is discussed in Chapter 9, Tie .
Filehandles, directory handles, and formats aren't quite first-class data types; they cannot be assigned to one another or passed as parameters, and you cannot create local versions of them. In Chapter 3, Typeglobs and Symbol Tables , we study why we want these facilities in the first place and the work-arounds to achieve them. This chapter focuses on a somewhat hidden data type called a typeglob and its internal representation, the understanding of which is crucial for obtaining information about the state of the interpreter ( meta-data ) and for creating convenient aliases.
Now let's turn to language issues not directly related to Perl data types.
Perl supports exception handling, including asynchronous exceptions (the ability to raise user-defined exception from signal handlers). As it happens, eval is used for trapping exceptions as well as for run-time evaluation, so Chapter 5, Eval , does double-duty explaining these distinct, yet related, topics.
Section 6.2, "Packages and Files" , details Perl's support for modular programming, including features such as run-time binding (in which the procedure to be called is known only at run-time), inheritance (Perl's ability to transparently use a subroutine from another class), and autoloading (trapping accesses to functions that don't exist and doing something meaningful). Chapter 7, Object-Oriented Programming , takes modules to the next logical step: making modules reusable not only from the viewpoint of a library user, but also from that of a developer adding more facets to the library.
Perl supports run-time evaluation: the ability to treat character strings as little Perl programs and dynamically evaluate them. Chapter 5 introduces the eval keyword and some examples of how this facility can be used, but its importance is truly underscored in later chapters, where it is used in such diverse areas as SQL query evaluation ( Chapter 11, Implementing Object Persistence ), code generation ( Chapter 17 ), and dynamic generation of accessor functions for object attributes ( Chapter 8, Object Orientation: The Next Few Steps ).
Three chapters are devoted to working with and understanding the Perl interpreter. There are two main reasons for delving into this internal aspect of Perl. One is to extend Perl, by which I mean adding a C module that can do things for which Perl is not well-suited or is not fast enough. The other is to embed Perl in C, so that a C program can invoke Perl for a specific task such as handling a regular expression substitution, which you may not want to code up in C.
Chapter 18, Extending Perl:A First Course , presents two tools ( xsubpp and SWIG ) to create custom dynamically loadable C libraries for extending the Perl interpreter.
Chapter 19, Embedding Perl:The Easy Way , presents an easy API that was developed for this book to enable you to embed the interpreter without having to worry about the internals of Perl.
But if you really want to know what is going on underneath or want to develop powerful extensions, Chapter 20 should quench your thirst (or drown you in detail, depending on your perspective).
I am of the opinion that an applications developer should master at least the following six major technology areas: user interfaces, persistence, interprocess communication and networking, parsing and code generation, the Web, and the operating system. This book presents detailed explanations of the first four topics (in Chapters Chapter 10, Persistence through Chapter 17 ). Instead of just presenting the API of publicly available modules, the book starts with real problems and develops useful solutions, including appropriate Perl packages. For example, Chapter 13, Networking: Implementing RPC , explains the implementation of an RPC toolkit that avoids deadlocks even if two processes happen to call each other at the same time. As another example, Chapter 11 , develops an "adaptor" to transparently send a collection of objects to a persistent store of your choice (relational database, plain file, or DBM file) and implements querying on all of them.
This book does not deal with operating system specific issues, partly because Perl hides a tremendous number of these differences and partly because these details will distract us from the core themes of the book. Practically all the code in this book is OS-neutral.
I have chosen to ignore web-related issues and, more specifically, CGI. This is primarily because there are numerous books[ 5 ] and tutorials on CGI scripting with Perl that do more justice to this subject than the limited space on this book can afford. In addition, developers of most interesting CGI applications will spend much more time with the concepts presented in this book than with the simple details of the CGI protocol per se .
[5] Refer to Shishir Gundavaram's book CGI Programming on the World Wide Web (O'Reilly)
|
|

|
|
| Why Perl? |
|
The Book's Approach |