 | Programming the Perl DBI |  |

Database proxying is the ability to forward database queries to a database, using an intermediate piece of software, the proxy, and return the results from those queries without the client program having any database drivers installed.
For example, a common use for a database proxy is for a client program located on a Unix machine to query a Microsoft Access database located on a Windows machine. Suppose the Unix machine has no ODBC software or drivers installed and thus doesn't know anything about ODBC. This means that it needs to forward any queries to a proxy server that does know about ODBC and the Access database. The proxy server then issues the query and gathers the results, which it then passes back to the client program for processing.
This functionality is extremely powerful, as it allows us to access databases on virtually any operating system from any other operating system, provided that they are both running Perl and the DBI. There is an additional benefit in terms of software distribution: if client PCs used Perl scripts to access an Oracle database located on a central Unix server, you don't have to undergo a potentially complex Oracle client software installation. DBI proxy capabilities make this client software unnecessary.
Furthermore, you can automatically add ``network awareness'' to types of databases that could never otherwise support such a thing. For example, with the DBI proxy capabilities, you could run a Perl script on a Windows machine that queries data from a CSV file over the network.
Finally, the DBI proxy architecture allows for on-the-fly compression of query and result data, and also encryption of that data. These two facilities make DBI a powerful tool for pulling large results sets of data over slow network links such as a modem. It also makes DBI a secure tool for querying sensitive data. We shall discuss these two topics in greater detail in a later section.
The DBI supports database proxying through two modules, DBD::Proxy and DBI::ProxyServer . DBD::Proxy is used by client programs to talk to a proxy server that is implemented with the DBI::ProxyServer module. Figure 8-1 illustrates the architecture.
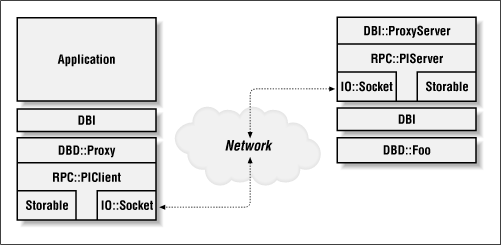
Because the DBI::ProxyServer module uses the underlying database drivers to actually interface with the databases, any type of database can be queried and manipulated via proxy, including CSV files and XBase (DBF) files. The DBI proxy architecture does not restrict you to using high-end databases such as Oracle or Informix.
So how do we use this proxy server? Let's look at the common example of a Perl program running on a Unix box that wants to query a Microsoft Access database running on a Windows machine.
The DBI proxy server is simply a layer on top of the DBI; it can only be a server for the data sources that the underlying DBI is able to connect to. So, before we get involved in setting up the proxy server to accept proxy client connections, we must install any database drivers that its clients may need. For our example of connecting to an Access database, we'll need to install the DBD::ODBC module.[69]
[69]If you have a compiler, you can get the source from CPAN and build it yourself, or, on Windows, just fetch and install a pre-built version using the PPM tool supplied with ActiveState Perl.
You will also need to configure your ODBC data source within the Windows ODBC Control Panel. For our megalithic database, let's call the ODBC data source archaeo.
We can test that this data source is correctly configured using the DBI Shell dbish locally on the Windows machine:
dbish dbi:ODBC:archaeo
or via a short script that can be run on your Windows machine:
use DBI; $dbh = DBI->connect( "dbi:ODBC:archaeo", "username", "password" ); $dbh->disconnect( );
If dbish connects, or if no errors occur when executing the script, it looks like everything's installed and configured correctly.
The easiest way to set up a DBI proxy server is to use the script called dbiproxy , which is distributed with the core DBI module. The DBI::ProxyServer module, used by dbiproxy, has a few prerequisite modules that must be installed in order for it to work: PlRPC and Net::Daemon . These can be downloaded and installed from CPAN using:
perl -MCPAN -e 'install Bundle::DBI'
Or, if you are running the ActiveState Perl for Windows, you can install these modules separately via PPM (since PPM currently does not currently support bundles).
The crucial information required by dbiproxy is the port number to which the proxy server should listen for incoming proxy client connections. If the port number is 3333, we can run the proxy server with the following command:
dbiproxy --localport 3333
This will start up the server; it's now waiting for connections. If you want to verify that the server is indeed up and running, you can run it with the --debug flag and the optional --logfile flag to specify where the debug output will go.
For example:
dbiproxy --localport 3333 --debug
will produce debug output either in the command prompt window on a Windows machine, and or via syslog(1) on a Unix machine. On Unix workstations, you can redirect the output to the current terminal with:
dbiproxy --localport 3333 --debug --logfile /dev/tty
This should behave correctly under most modern Unix platforms.
Now that we have configured our proxy server to sit and wait on port 3333 on our Windows machine, we need to tell the client Perl program on the Unix machine to use that proxy server instead of attempting to make a direct database connection itself.
For example, the ODBC test script above connects directly via the DBD::ODBC module with the following DBI->connect( ) call:
$dbh = DBI->connect( "dbi:ODBC:archaeo", "username", "password" );
This is fine for local connections, but how do we translate that into something the proxy server can use?
DBD::Proxy makes liberal use of the optional arguments that can be added to a DSN when specifying which database to connect to. DBD::Proxy allows you to specify the hostname of the machine upon which the proxy server is running, the port number that the proxy server is listening to, and the data source of the database that you wish the proxy server to connect to.
Therefore, to connect to the ODBC database called archaeo on the Windows machine fowliswester with a proxy server running on port 3333, you should use the following DBI- >connect( ) syntax:
$dsn = "dbi:ODBC:archaeo"; $proxy = "hostname=fowliswester;port=3333"; $dbh = DBI->connect( "dbi:Proxy:$proxy;dsn=$dsn", '', '' );
This looks quite long-winded, but it's a very compact and portable way to make a pass-through connection to a remote database by proxy.
Once you have connected to the proxy server and it connects to the desired data source, a valid database handle will be returned, allowing you to issue queries exactly as if you had connected directly to that database. Therefore, when using a proxy server, only the DBI->connect( ) call will vary -- which is exactly the same behavior as changing from one database to another.
Having said that, it's even possible to use the proxy without editing your programs at all. You just need to set the DBI_AUTOPROXY environment variable and the DBI will do the rest. For the example above, you can leave the connect( ) statement referring to dbi:ODBC:archaeo and just set the DBI_AUTOPROXY environment variable to:
dbi:Proxy:hostname=fowliswester;port=3333
The value contained within the DBI_AUTOPROXY value has the DSN specified in the DBI->connect( ) call concatenated to it to produce the correct proxy DSN. For example:
$ENV{DBI_AUTOPROXY} = 'dbi:Proxy:hostname=fowliswester;port=3333';
$dbh = DBI->connect( "dbi:ODBC:archaeo", "username", "password" );would result in the script attempting a connection to the DSN of:
dbi:Proxy:hostname=fowliswester;port=3333;dsn=dbi:ODBC:archaeo
The other important point to stress regarding the client is that you do not need to install any database drivers whatsoever. The database drivers are used only by the proxy server.
The DBI proxy architecture is implemented on top of a couple of lower-level Perl networking modules such as PlRPC and, in the case of DBI::ProxyServer , Net::Daemon . As such, these modules have a lot of features that are inherited into the DBI proxy architecture, such as powerful access-list configuration and on-the-fly compression and ciphering.
We shall look at each of these topics in more detail and explain how they can be used effectively in your software.
The Net::Daemon, RPC::PlServer, and DBI::ProxyServer modules share a common configuration filesystem because of the ways that RPC::PlServer inherits from Net::Daemon and DBI::ProxyServer inherits from RPC::PlServer.[70]
[70]All these modules, including DBD::Proxy were designed and implemented by a single author, Jochen Wiedmann. Thank you, Jochen.
The configuration files for these modules are expressed as Perl scripts in which various options are set. The most useful options are those that allow you to specify access lists. Access lists allow you to control which machines may connect to the proxy server, and the mode that the network transport between these machines and the proxy server operates in.
For example, if you had a secure corporate LAN containing a database server and client PCs, you might say that the client PCs could connect to the central database via a proxy server without any authentication or encryption. That is, a PC connected to the LAN is trusted.
However, computers in employees' houses that need access to the database are not trusted, as the data flowing across the phone line might be somehow intercepted by competitors. Therefore, the network transport between these machines and the central database server is encrypted.
A sample configuration file for the proxy server might look like:
{
facility => 'daemon',
pidfile => '/var/dbiproxy/dbiproxy.pid',
user => 'nobody',
group => 'nobody',
localport => '3333',
mode => 'fork',
# Access control
clients => [
# Accept the local LAN ( 192.168.1.* )
{
mask => '^192\.168\.1\.\d+$',
accept => 1
},
# Accept our off-site machines ( 192.168.2.* ) but with a cipher
{
mask => '^192\.168\.2\.\d+$',
accept => 1,
# We'll discuss secure encryption ciphers shortly
cipher => Crypt::IDEA->new( 'be39893df23f98a2' )
},
# Deny everything else
{
mask => '.*',
accept => 0
}
]
}The dbiproxy script can be started with this custom configuration file in the following way:
dbiproxy --configfile <filename>
For example, if we had saved the above configuration file as proxy.config, we could start up dbiproxy with the command:
dbiproxy --configfile proxy.config
Furthermore, the DBI::ProxyServer configuration file also allows us to apply access lists to individual types of statements. For example, you might want the workstations of sales operators to be able to query data, but not change it in any way. This can be done using the following configuration options:
# Only allow the given SELECT queries from sales
# workstations ( 192.168.3.* )
clients => [
{
mask => '^192\.168\.3\.\d+$',
accept => 1,
sql => {
select => 'SELECT name, mapref FROM megaliths WHERE name = ?'
}
},
]The other statement restriction keys that you can use are insert, update, and delete. For example, if you wished to allow only particular DELETE statements to be executed, you could write the following access control:
sql => {
delete => 'DELETE FROM megaliths WHERE id = ?'
}This control would refuse any DELETE statements that did not conform to the given control mask, such as someone maliciously executing DELETE FROM megaliths.
Therefore, the access control functionality inherent in DBI::ProxyServer and its parent modules can be used to build complex (yet flexible) networked database systems quickly and easily.
In the previous example, we discussed the possibility of a user querying the database via a modem line and proxy server. Suppose the user executes a query that returns 100,000 rows of data, each row being around 1 KB. That's a lot of information to pull across a slow network connection.
To speed things up, you could configure the proxy server to use on-the-fly compression (via the Compress::Zlib module) to clients querying the database over dial-up connection. This will radically reduce the quantity of data being transferred across the modem link. You can do this by running the dbiproxy script with the additional arguments of:
--compression gzip
which specifies that the GNU gzip compression method should be used.
In order for your client to be able to send and receive compressed data from the DBI proxy server, you also must tell the proxy driver to use a compressed data stream. This is done by specifying the additional DSN key/value pair of compression=gzip when connecting to the database. For example:
$proxyloc = 'hostname=fowliswester;port=3333';
$compression = 'compression=gzip';
$dsn = 'dbi:ODBC:archaeo';
$dbh = DBI->connect( "dbi:Proxy:$proxyloc;$compression;dsn=$dsn",
"username", "password" );The trade-off is the cost in CPU time for the proxy server and proxy client to compress and decompress the data, respectively. From a client perspective, this is probably not an issue, but the proxy server might be affected, especially if several large queries are being executed simultaneously, with each requiring compression.
However, compression is a useful and transparent feature that can increase the efficiency of your networks and databases when using DBI proxying.
The final configuration topic that we will cover for the DBI proxy architecture is that of on-the-fly encryption of data.
This functionality is useful if you are implementing a secure networked database environment where database operations might be occurring over nonsecure network links, such as a phone line through a public ISP. For example, an employee at home might use his or her own ISP to access a secure company database. Or you might wish to make an e-commerce transaction between two participating financial institutions.
Both of these examples are prime candidates for using the cipher mechanism in DBI::ProxyServer. Ciphering is implemented within the RPC::PlClient and RPC::PlServer modules. This allows DBD::Proxy and DBI::ProxyServer to use those mechanisms by means of inheritance. The actual ciphering mechanism uses external modules such as Crypt::IDEA or Crypt::DES for key generation and comparison.[71]
[71]The technical differences and ins and outs of these algorithms are way beyond the scope of this book. You should consult the documentation for these modules for pointers to texts discussing the various cryptographic algorithms.
The very basic premise of an encrypted data stream is that the client and server generate keys, which are then sent to each other. When the client wishes to transmit data to the server, it encrypts the data with the server's key. Similarly, if the server wishes to send data to the client, it uses the client's key to encrypt it first. This system allows the client and server to decode the incoming data safely. Since the data is encrypted before transmission and decoded after receipt, anyone snooping on the network will see only encrypted data.
Therefore, to support encryption via DBI proxying, we need to configure both the client connecting to the proxy server to use encryption and also configure the server to use the same encryption.
The configuration of the client is trivial and is simply a case of specifying additional arguments to the DBI->connect( ) call. For example, to use Crypt::IDEA as the underlying ciphering method, we can write:
use Crypt::IDEA; ### The key is a random, but long, hexadecimal number! $key = 'b3a6d83ef3187ac4'; ### Connect to the proxy server $dbh = DBI->connect( "dbi:Proxy:cipher=IDEA;key=$key;...", '', '' );
The actual key creation occurs by instantiating a new object of the given cipher type (in this case Crypt::IDEA) with the given key value. This cipher object is then passed to the proxy server. We could have used the Crypt::DES module to provide the underlying encryption services by simply changing cipher=IDEA to cipher=DES.[72] This demonstrates the configurability of the DBI proxy encryption mechanisms.
[72]We would also need to change the use Crypt::IDEA; line accordingly.
For example, if we were transmitting sensitive but not confidential data from our internal database to someone's home PC, we might wish to use the relatively low-grade encryption offered by Crypt::DES. However, if more confidential data was being transmitted, we might wish to switch over to using the stronger but slower encryption of Crypt::IDEA.
Configuring the proxy server is equally straightforward and is achieved by specifying the encryption rules within the proxy server configuration file. For example, a simple proxy server configuration that encrypts all traffic with Crypt::IDEA can be written as:
require Crypt::IDEA;
### The key to encrypt data with
$key = 'b3a6d83ef3187ac4';
{
clients => [ {
'accept' => 1,
'cipher' => IDEA->new( pack( "H*", $key ) )
} ]
}The important aspect of this configuration file is that the key being used to create the Crypt::IDEA object matches that used by the client programs connecting to this proxy server. If the keys do not match, no connection will be made, as the client and server will not be able to decode data flowing over the network connection.
|  | |
| 8. DBI Shell and Database Proxying |  | A. DBI Specification |

Copyright © 2001 O'Reilly & Associates. All rights reserved.