 | CGI Programming with Perl |  |

SSI and HTML::Template are simple template solutions that allow you to add basic tags to static and dynamic HTML files. The HTML::Embperl module, often referred to simply as Embperl, takes a different approach; it parses HTML files for Perl code, allowing you to shift your code into your HTML documents. This approach is similar to Java Server Pages or Microsoft's ASP technology that moves programming languages into documents. There are actually several modules available for embedding Perl within HTML documents, including Embperl, ePerl, HTML::EP, HTML::Mason, and Apache::ASP. We'll look at Embperl and Mason in this chapter.
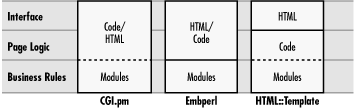
The theory behind moving code into HTML pages is somewhat different from the standard reason for using HTML templates. Both strategies attempt to separate the interface from the program logic, but they draw the lines at different places (see Figure 6-2). Basic template solutions like HTML::Template draw the line between HTML and all code, at least as much as possible. For Embperl and similar solutions, the logic for creating the page is folded into the HTML for the page, but common business rules are collected into modules that can be shared across pages. Business rules are those core elements of your application or applications that are separate from the interface, data management, etc. Of course, in practice not everyone creates as many modules as the model suggests, and you can create modules like this with any of the approaches (as the dotted lines suggest). Thus, the model for complex template solutions like Embperl and ASP often end up looking like CGI.pm, except that instead of including HTML in the code, the code is included in the HTML. This isn't a bad thing, of course. Both CGI.pm and Embperl are excellent solutions for tying together HTML and program code, and you should choose whatever solution makes the most sense to you for each project. The point is simply that those who argue about the different approaches of using CGI.pm versus templates sometimes are not as far apart as they may seem; the extremes of each seem more alike than different.[8]
[8]Jason Hunter (author of Java Servlet Programming from O'Reilly & Associates) made a similar argument from a Java perspective. His article, "The Problem with JSP," is available at http://www.servlets.com/soapbox/problems-jsp.html.
Embperl can be used in a variety of ways. You can call Embperl from your CGI scripts and have it parse a template file, just as you would with HTML::Template. In this mode, it simply gives you much more power than the latter since you can include full Perl expressions in the template (at the expense of making your templates more complex). However, because you have the entire Perl language at your disposal inside your template files, it really isn't necessary to have an additional CGI script initiate the request. Thus, Embperl can be configured as a handler so that your template files can become the target of HTTP requests; this works similar to the way that the SSI handler allows .shtml files to be the target for HTTP requests.
Embperl can also be used with or without mod_perl. It is optimized for mod_perl, but it is written in C as well as Perl, so the compiled C code does run faster than a comparable Perl module would if you are not using mod_perl.
To call Embperl from your CGI scripts, use its Execute function and pass it the path to the template along with any parameters to use when parsing the template. For example,
my $template = "/usr/local/apache/htdocs/templates/welcome.epl"; HTML::Embperl::Execute( $template, $time, $greeting );
This parses welcome.epl, using the values of $time and $greeting as parameters, and writes the result to STDOUT. Note that we called the function as HTML::Embperl::Execute and not simply Execute. Embperl doesn't export any symbols, nor is it an object-oriented module. Thus, you must fully qualify the Execute function.
You can also call Execute and pass it a reference to a hash with named parameters. This gives you more options when using Embperl. For example, you can read the template input from a scalar variable instead of a file and you can write the output to a file or a variable instead of STDOUT.
Here is how we can parse the welcome.epl template and write the result to welcome.html:
my $template = "/usr/local/apache/htdocs/templates/welcome.epl";
my $output = "/usr/local/apache/htdocs/welcome.html";
HTML::Embperl::Execute( { inputfile => $template,
param => [ $time, $greeting ],
outputfile => $output } );Embperl also has options to cache compiled versions of pages when used with mod_perl. Refer to the Embperl documentation for the full list of parameters.
If you are using mod_perl, you would register Embperl as a handler by adding the following to httpd.conf (or srm.conf if used):
<Files *.epl>
SetHandler perl-script
PerlHandler HTML::Embperl
Options ExecCGI
</files>
AddType text/html .eplThen any file that has a .epl suffix will be parsed and executed by Embperl.
If you aren't using mod_perl but want your Embperl files to handle requests directly without a CGI script, you can also use the embpcgi.pl CGI script that is distributed with Embperl. You place this script in your CGI directory and pass it the URL of the file to parse as part of its path info. For example, you might have a template file in the following path:
/usr/local/apache/htdocs/templates/welcome.epl
To have Embperl handle this file via embpcgi.pl, you would use the following URL:
http://localhost/cgi/embpcgi.pl/templates/welcome.epl
As a security feature, embpcgi.pl will only handle files that are located within your web server's document root. This prevents someone from trying to get at important files like /etc/passwd. Unfortunately, this means that people can attempt to access your Embperl file directly. For example, someone could view the source to our welcome.epl file with the following URL:
http://localhost/templates/welcome.epl
Allowing people to view the source code of executable files on your web server is not a good idea. Thus, if you use embpcgi.pl, you should create a standard directory where you will store your Embperl templates and disable direct access to these files. Here is how you would do this for Apache. Add the following directives to httpd.conf (or access.conf if used) to disable access to any file below the directory named templates:
<Location /templates> deny from all </Location>
This works by denying access to this directory (and any subdirectories) to all HTTP request from all web clients.
Some HTML editors restrict authors from including tags that they do not recognize as proper HTML tags. This can be a problem when using these editors to create HTML templates that often have their own style of custom tags. Embperl was created with this in mind. It does not use commands that resemble HTML tags so you can enter code as text in WYSIWYG editors. Embperl will also interpret any characters that have been HTML encoded (such as > instead of >) and remove extraneous tags (such as and <BR>) within Perl code before that code is evaluated.
In an Embperl document, Perl commands are surrounded by a bracket plus another character, which we will refer to as a bracket pair. As an example, [+ is a starting bracket pair and +] is an ending bracket pair. Embperl supports a number of bracket pairs and treats the contents differently for each. Example 6-10 provides a simple Embperl document that uses most of them.
<HTML>
<HEAD>
<TITLE>A Simple Embperl Document</TITLE>
</HEAD>
<BODY BGCOLOR="white">
<H2>A Simple Embperl Document</H2>
[- $time = localtime -]
<P>Here are the details of your request at [+ $time +]:</P>
<TABLE>
<TR>
<TH>Name</TH>
<TH>Value</TH>
</TR>
[# Output a row for each environment variable #]
[$ foreach $varname ( sort keys %ENV ) $]
<TR>
<TD><B>[+ $varname +]</B></TD>
<TD>[+ $ENV{$varname} +]</TD>
</TR>
[$ endforeach $]
</TABLE>
</BODY>
</HTML>Embperl recognizes blocks of code within the following bracket pairs:
These brackets are typically used for variables and simple expressions. Embperl executes the enclosed code and replaces it with the result of the last expression evaluated. This is evaluated in a scalar context, so something like this:
[+ @a = ( 'x', 'y', 'z' ); @a +]
yields an output of "3" (the number of elements in the array) and not "xyz" or "x y z".
These brackets are used for most of your program logic such as interfacing with outside modules, assigning values to variables, etc. Embperl executes the enclosed code and discards the result.
These brackets are used with subroutines declarations and other code that needs to be initialized only once. Embperl treats these bracket pairs just like [- ... -] except that it only executes the enclosed code once. This distinction is most relevant to with mod_perl: because Embperl stays resident between HTTP requests, having code run once means once per the life of the web server child, which may handle a hundred requests (or more). With CGI, code within this block is only executed once per request. These bracket pairs were introduced in Embperl 1.2.
These brackets are used with Embperl's meta-commands, such as the foreach and endforeach control structure we used in our example. Embperl's meta-commands are listed in Table 6-6 later in this chapter.
These brackets are used when working with local variables and for Perl control structures. Embperl treats this like [- ... -] except that it executes all the code in the these blocks in a common scope (sort of, see the Section 6.4.2.2, "Variable scope" subsection below). This allows code within these blocks to share local variables. They can also contain Perl control structures. Instead of using Embperl's meta-commands as control structures, we could have used Perl's foreach loop instead of Embperl's to create the table in our previous example:
[# Output a row for each environment variable #]
[* foreach $varname ( sort keys %ENV ) { *]
<TR>
<TD><B>[+ $varname +]</B></TD>
<TD>[+ $ENV{$varname} +]</TD>
</TR>
[* } *]The difference is brackets versus meta-command blocks. Note that code within [* and *] must end with a semicolon or a curly bracket, and these blocks are evaluated even inside Embperl comment blocks (see below). These bracket pairs were introduced in Embperl 1.2.
These brackets are used for comments. Embperl ignores and strips anything between these bracket pairs so the contents do not end up in the output sent to the client. These can also be used to remove large sections of HTML or code during testing, but unfortunately this does not work for code within [* ... *], since these blocks are evaluated first. These bracket pairs were introduced in Embperl 1.2.
Because blocks begin with [ in Embperl, you must use [[ if you need to output the [ character in your HTML. There is no need to escape ] or other characters. Also, Embperl ties STDOUT to its output stream so you can use print within Embperl blocks and it will behave correctly.
Each block of code within a set of bracket pairs is evaluated as a separate block within Perl. This means that each one has a separate variable scope. If you declare a lexical variable (a variable declared with my) in one block, it will not be visible in another block. In other words, this will not work:
[- my $time = localtime -] <P>The time is: [+ $time +].</P>
The result is roughly analogous to the following in Perl:
&{sub { my $time = localtime }};
print "<P>The time is: " . &{sub { $time }} . ".</P>";Similarly, pragmas that depend on scope such as use strict will only affect the current block of code. To enable the strict pragma globally, you must use the var meta-command (see Table 6-6).
The [* ... *] blocks are a little different. They all share a common scope so local variables (variables declared with local) can be shared between them. However, lexical variables still can not. This does not mean that you should entirely abandon declaring your variables with my in Embperl.
Lexical variables are still useful as temporary variables that you only need within a particular block. Using lexical variables for temporary variables is more efficient than using global variables because they are reclaimed by Perl as soon as the surrounding block ends. Otherwise, they persist until the end of the HTTP request. Under CGI, of course, all global variables are cleaned up at the end of the request because perl exits. However, even when running under mod_perl, by default Embperl undefines all global variables created within the scope of your pages at the end of each HTTP request.
Embperl offers several meta-commands for creating control structures plus other miscellaneous functions shown in Table 6-6. The parentheses shown with some of the control structures are optional in Embperl, but including them can make these commands clearer and look more like Perl's corresponding control structures.
|
Meta-command |
Description |
|---|---|
[$ foreach $loop_var ( list ) $] |
Similar to Perl's foreach control structure, except $loop_var is required. |
[$ endforeach $] |
Indicates the end of a foreach loop. |
[$ while ( expr ) $] |
Similar to Perl's while control structure. |
[$ endwhile $] |
Indicates the end of a while loop. |
[$ do $] |
Indicates the beginning of an until loop. |
[$ until ( expr ) $] |
Similar to Perl's until control structure. |
[$ if ( expr ) $] |
Similar to Perl's if control structure. |
[$ elsif ( expr ) $] |
Similar to Perl's elsif control structure. |
[$ else $] |
Similar to Perl's else control structure. |
[$ endif $] |
Indicates the end of an if conditional. |
[$ sub subname $] |
This allows you to treat a section containing both HTML and Embperl blocks as a subroutine that can be called as a normal Perl subroutine or via Embperl's Execute function. |
[$ endsub $] |
Indicates the end of a sub body. |
[$ var $var1 @var2 %var3 ... $] |
This command is equivalent to the following in a Perl script: use strict; use vars qw( $var1 @var2 %var3 ... ); Your pages will be more efficient if you use this, especially when running with mod_perl. Remember, however, that if you do, you must declare every variable here that is shared between Embperl blocks because of the scope restriction (see Section 6.4.2.2, "Variable scope", earlier). |
[$ hidden [ %input %used ] $] |
This generates hidden fields for all elements in the first hash that are not in the second hash. Both hashes are optional, and one typically uses Embperl's default, which are %fdat and %idat. %fdat contains the name and values of the fields the user submitted, and %idat contains the names and values of the fields that have been used as elements in the current form (see Section 6.4.4, "Global Variables", later). |
Embperl monitors and responds to HTML as it is output. You can have it construct tables and prefill form elements for you automatically.
If you use the $row, $col, or $cnt variables in code within a table, Embperl will loop over the contents of the table, dynamically build the table for you, and set these variables to the current row index, the current column index, and the number of cells output, respectively, with each iteration. Embperl interprets the variables as follows:
If $row is present, everything between <TABLE> and </TABLE> is repeated until the expression containing $row is undefined. Rows consisting entirely of <TH> ... </TH> cells are considered headers and are not repeated.
If $col is present, everything between <TR> and </TR> is repeated until the expression containing $col is undefined.
$cnt is used in the same manner for either rows or columns if it is present and $row or $col are not.
Let's look at an example. Because $row and $col are set to the index of the current row and column, they are typically used as array indices when building tables, as shown here:
[- @sports = ( [ "Windsurfing", "Summer", "Water" ],
[ "Skiing", "Winter", "Mountain" ],
[ "Biking", "All Year", "Hills" ],
[ "Camping", "All Year", "Desert" ] ); -]
<TABLE>
<TR>
<TH>Sport</TH>
<TH>Season</TH>
<TH>Terrain</TH>
</TR>
<TR>
<TD>[+ $sports[$row][$col] +]</TD>
</TR>
</TABLE>The previous code will create the following table:
<TABLE>
<TR>
<TH>Sport</TH>
<TH>Season</TH>
<TH>Terrain</TH>
</TR>
<TR>
<TD>Windsurfing</TD>
<TD>Summer</TD>
<TD>Water</TD>
</TR>
<TR>
<TD>Skiing</TD>
<TD>Winter</TD>
<TD>Mountain</TD>
</TR>
<TR>
<TD>Biking</TD>
<TD>All Year</TD>
<TD>Hills</TD>
</TR>
<TR>
<TD>Camping</TD>
<TD>All Year</TD>
<TD>Desert</TD>
</TR>
</TABLE>If you use $row within a list or select menu, Embperl will repeat each element until $row is undefined, just as it does with tables. For select menus, Embperl will also automatically check options that match name and value pairs in %fdat and add names and values to %idat (see below).
Outputting input and text area tags with Embperl is similar to outputting these tags with CGI.pm: if you create an element with a name matching an existing parameter, the value of the parameter is filled in by default. When an element is created, Embperl checks whether the name of that element exists within the %fdat hash (see below); if it does, then its value is automatically filled in. Also, as HTML elements are generated, Embperl adds the name-value (if given) to %idat.
Embperl defines a number of global variables that you can use within your templates. Here is a list of the primary variables:
This should look familiar. Embperl sets your environment variables to match standard CGI environment variables when running under mod_perl.
This contains the name and value of all form fields that have been passed to your CGI script. Embperl, like CGI.pm, does not distinguish between GET and POST requests and loads parameters from either the query string or the body of the request as appropriate. If an element has multiple values, these values are separated by tabs.
This contains the name and value of the form fields that have been created on the current page.
This is only available when running under mod_perl with the Apache::Session module. You can use this hash to store anything and it will be available to every future request for the same page, even if those requests are to different httpd child processes.
This is only available when running under mod_perl with the Apache::Session module. You can use this hash to store anything and it will be available to any future request made by the same user. This sends a HTTP cookie to the user, but no cookies are sent if this hash is not used in your code. See Section 11.3, "Client-Side Cookies".
If you use the Execute function to invoke Embperl pages, the parameters you supply are available to your page via this variable.
Let's look at an example of using Embperl. For our example, we will create a basic "What's New" section that displays the headlines of recent stories. If users click on a headline, they will be able to read the story. This in itself isn't that impressive, but we will create administrative pages that make it very simple for someone administering the site to add, delete, and edit news stories.
There are a total of four pages to our application, the "What's New" page that displays current headlines; an article page where users can read a story; a main administrative page that lists the current headlines and provides buttons for adding, deleting, and editing stories; and an administrative page that provides a form for entering a headline and article body, which is used for both editing existing stories as well as creating new stories. These pages are shown later in Figure 6-3 through Figure 6-6.
Traditional Embperl solutions use .epl files as the target of our requests. This example will work either via mod_perl or embpcgi.pl.
Let's look at the main "What's New" page first. The code for news.epl is shown in Example 6-11.
<HTML>
[!
use lib "/usr/local/apache/lib-perl";
use News;
!]
[- @stories = News::get_stories( ) -]
<HEAD>
<TITLE>What's New</TITLE>
</HEAD>
<BODY BGCOLOR="white">
<H2>What's New</H2>
<P>Here's the latest news of all that's happening around here.
Be sure to check back often to keep up with all the changes!</P>
<HR>
<UL>
<LI>
[- ( $story, $headline, $date ) = @{ $stories[$row] } if $stories[$row] -]
<A HREF="article.epl?story=[+ $story +]">[+ $headline +]</A>
<I>[+ $date +]</I>
</LI>
</UL>
[$ if ( !@stories ) $]
<P>Sorry, there aren't any articles available now. Please check
back later!</P>
[$ endif $]
</BODY>
</HTML>The result looks like Figure 6-3.
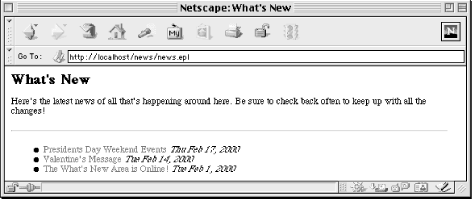
Embperl programs are much easier to read and maintain if you reduce the amount of Perl that is included in the HTML. We do this by moving much of our code into a common module, News.pm, which we place in /usr/local/apache/perl-lib.
We'll look at the News module in a moment, but let's finish looking at news.epl first. We call the News module's get_stories function. This returns an array of stories with each element of the array containing a reference to an array of the story number, its headline, and the date it was written.
Thus, within our unordered list later in the file, we loop over each story using Embperl's special $row variable and extract these elements of each story to the $story, $headline, and $date variables. Embperl will loop and create a list item until the expression containing $row evaluates to an undefined value. We then use these variables to build a link to a story as a list element.
If there are no stories, then we print a message telling the user this. That's all there is to this file. Example 6-12 shows a relevant section of the News module.
#!/usr/bin/perl -wT
package News;
use strict;
use Fcntl qw( :flock );
my $NEWS_DIR = "/usr/local/apache/data/news";
1;
sub get_stories {
my @stories = ( );
local( *DIR, *STORY );
opendir DIR, $NEWS_DIR or die "Cannot open $NEWS_DIR: $!";
while ( defined( my $file = readdir DIR ) ) {
next if $file =~ /^\./; # skip . and ..
open STORY, "$NEWS_DIR/$file" or next;
flock STORY, LOCK_SH;
my $headline = <STORY>;
close STORY;
chomp $headline;
push @stories, [ $file, $headline, get_date( $file ) ];
}
closedir DIR;
return sort { $b->[0] <=> $a->[0] } @stories;
}
# Returns standard Unix timestamp without the time, just the date
sub get_date {
my $filename = shift;
( my $date = localtime $filename ) =~ s/ +\d+:\d+:\d+/,/;
return $date;
}We store the path to the news directory in $NEWS_DIR. Note that we use a lexical variable here instead of a constant because if this script is used with mod_perl, as is often the case with Embperl, using constants can generate extra messages in the log file. We'll discuss why this happens in Section 17.3, "mod_perl".
The format for our article files is rather basic. The first line is the headline, and all following lines are the body of the article, which should contain HTML formatting. The files are named according to the time that they are saved, using the result of Perl's time function -- the number of seconds after the epoch.
For the sake of this example we will assume that there is only one administrator who has access to create and edit files. If this were not the case, we would need to create a more elaborate way to name the files to prevent two people from creating stories at the same second. Plus, we would need to create a system to avoid having two administrators edit the same file at the same time; one way to do this would be to have the edit page retrieve the current time into a hidden field when it loads a file for editing, which could then be compared against the last modification time of the file when the file is saved. If the file has been modified since it was loaded, a new form would need to be presented to the administrator showing both sets of changes so they can be reconciled.
The get_stories function opens this news directory and loops through each file. It skips any files starting with a dot, including the current and parent directories. If we encounter any system errors reading directories we die; if we have problems reading a file, we skip it. Filesystem errors are not common, but they can happen; if you wish to generate a more friendly response to the user than a cryptic 500 Internet Service Error, use CGI::Carp with fatalsToBrowser to catch any die calls.
We get a shared lock on the file to make sure that we are not reading a file that is in the process of being written by the administrator. Then we read the story's headline and add the story's file number, headline, and date created to our list of stories. The get_date function simply generates a Unix timestamp from the file number via Perl's localtime function. That looks like this:
Sun Feb 13 17:35:00 2000
It then replaces the time with a comma in order to get a basic date that looks like this:
Sun Feb 13, 2000
Finally, we sort the list of stories from largest to smallest according to the article number. Because this is the same as the date the file was created, newest headlines will always appear at the beginning of the list.
When the user selects a headline from the list, the application fetches the corresponding article. Example 6-13 shows the page that displays the articles.
<HTML>
[!
use lib "/usr/local/apache/lib-perl";
use News;
!]
[- ( $headline, $article, $date ) = News::get_story( $fdat{story} ) -]
<HEAD>
<TITLE>[+ $headline +]</TITLE>
</HEAD>
<BODY BGCOLOR="white">
<H2>[+ $headline +]</H2>
<P><I>[+ $date +]</I></P>
[+ local $escmode = 0; $article +]
<HR>
<P>Return to <A HREF="news.epl">What's New</A>.</P>
</BODY>
</HTML>The result looks like Figure 6-4.
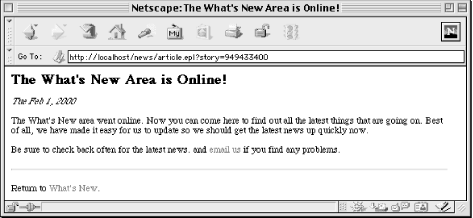
Because most of the work is done by the News module, this file is also quite simple. The links to this page from the main "What's New" page include a query string that specifies the number of the story to view. We use Embperl's special %fdat hash to retrieve the number of the story and pass it to the News::get_story function, which gives us the headline, article contents, and date of the article.
Then we simply need to include tags for these variables in our document where we want to display the data. $article requires some extra consideration. The body of the article contains HTML, but by default Embperl escapes any HTML generated by your Perl blocks, so for example, <P> will be converted to <P>. In order to disable this, we set Embperl's special $escmode variable to 0, and because we provide a local scope to the variable, this change only lasts for the current block and the former value of $escmode is reset after the article is output.
Example 6-14 contains the get_story function from the News module.
sub get_story {
my( $filename ) = shift( ) =~ /^(\d+)$/;
my( $headline, $article );
unless ( defined( $filename ) and -T "$NEWS_DIR/$filename" ) {
return "Story Not Found", <<END_NOT_FOUND, get_time( time );
<P>Oops, the story you requested was not found.</P>
<P>If a link on our What's New page brought you here, please
notify the <A HREF="mailto:$ENV{SERVER_ADMIN}">webmaster</A>.</P>
END_NOT_FOUND
}
open STORY, "$NEWS_DIR/$filename" or
die "Cannot open $NEWS_DIR/$filename: $!";
flock STORY, LOCK_SH;
$headline = <STORY>;
chomp $headline;
local $/ = undef;
$article = <STORY>;
return $headline, $article, get_date( $filename );
}This function takes the story number as a parameter, and the first thing this function does is verify that it is the expected format. The regular expression assignment followed by the defined test may seem like a roundabout way to test this, but we do this in order to untaint the filename; we explain tainting and why it's important in Section 8.4, "Perl's Taint Mode". Finally we make sure that this story exists and is a text file.
If any of our checks fail, we return an error to the user formatted like a standard story. Otherwise, we open the file read the headline and contents, get its date, and return this to the page.
Now let's look at the administrative pages. The administrative pages should be placed in a subdirectory beneath the other files. For example, the files could be installed in the following locations:
.../news/news.epl .../news/article.epl .../news/admin/edit_news.epl .../news/admin/edit_article.epl
This enables us to configure the web server to restrict access to the admin subdirectory. Example 6-15 shows the main administrative page, admin_news.epl.
<HTML>
[!
use lib "/usr/local/apache/lib-perl";
use News;
!]
[-
if ( my( $input ) = keys %fdat ) {
my( $command, $story ) = split ":", $input;
$command eq "new" and do {
$http_headers_out{Location} = "edit_article.epl";
exit;
};
$command eq "edit" and do {
$http_headers_out{Location} = "edit_article.epl?story=$story";
exit;
};
$command eq "delete" and
News::delete_story( $story );
}
@stories = News::get_stories( )
-]
<HEAD>
<TITLE>What's New Administration</TITLE>
</HEAD>
<BODY BGCOLOR="white">
<FORM METHOD="POST">
<H2>What's New Administration</H2>
<P>Here you can edit and delete existing stories as well as create
new stories. Clicking on a headline will take you to that article
in the public area; you will need to use your browser's Back button
to return.</P>
<HR>
<TABLE BORDER=1>
<TR>
[- ( $story, $headline, $date ) = @{ $stories[$row] } if $stories[$row] -]
<TD>
<INPUT TYPE="submit" NAME="edit:[+ $story +]" VALUE="Edit">
<INPUT TYPE="submit" NAME="delete:[+ $story +]" VALUE="Delete"
onClick="return confirm('Are you sure you want to delete this?')">
</TD>
<TD>
<A HREF="../article.epl?story=[+ $story +]">[+ $headline +]</A>
<I>[+ $date +]</I>
</TD>
</TR>
</TABLE>
<INPUT TYPE="submit" NAME="new" VALUE="Create New Story">
</FORM>
<HR>
<P>Go to <A HREF="../news.epl">What's New</A>.</P>
</BODY>
</HTML>The result looks like Figure 6-5.
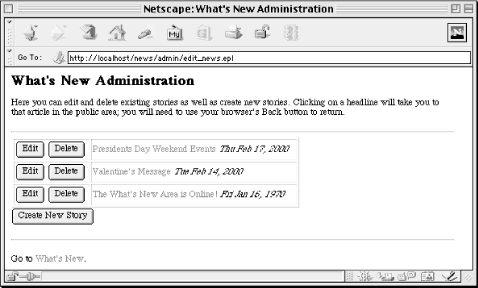
This page must handle a few different requests. If it receives a parameter, it uses a series of conditions to determine how to handle the request. Let's return to these statements after looking at the rest of the file because when the administrator first visits this page, there are no parameters.
Like news.epl, we fetch an array of stories from get_stories, but instead of creating an ordered list and looping over list items, we output a table and loop over rows in this table. For each story, we output a corresponding Edit and Delete button as well as a link to the story. Note that the name of the Edit and Delete buttons contain the command as well as the number of the story separated by a colon. This allows us to pass both pieces of information when the administrator clicks on a button, without restricting us from changing the label of the button. Finally, we add a submit button to the bottom of the page to allow the administrator to add a new story.
All the form elements on these page are submit buttons, and they will only send a name-value pair if they are clicked. Thus, if the administrator clicks a button, the browser will request the same page again, passing a parameter for the selected button. Returning to the conditions at the top of the file, if there is a parameter passed to this file, it is split by colon into $command and $story.
You may have noticed that if the administrator selects the button to create a new story, then the supplied parameter will not include a colon. That's okay because in this case, split will set $command to "new" and $story to undef. If $command is set to "new", we forward the user to the edit_article.epl file. To do this, we assign Embperl's special %http_headers_out variable. Setting the "Location" key to a value outputs a Location HTTP header; we can then exit this page.
If the administrator edits an existing story, we also forward to the edit_article.epl file and exit, but in this case we pass the story number as part of the query string. If the administrator deletes a story, we invoke the delete_story function from our News module and continue processing. Because we gather the list of stories after this deletion, this page will display the updated list of headers.
We also add a JavaScript handler to the delete button to prevent stray mouse clicks from deleting the wrong file. Even if you have decided not to use JavaScript on your public site, it can be very useful for administrative pages with limited access such as this, where you typically can be more restrictive about the browsers supported.
Finally, Example 6-16 presents edit_article.epl, the page that allows the administrator to create or edit articles.
<HTML>
[!
use lib "/usr/local/apache/lib-perl";
use News;
!]
[-
if ( $fdat{story} ) {
( $fdat{headline}, $fdat{article} ) =
News::get_story( $fdat{story} );
}
elsif ( $fdat{save} ) {
News::save_story( $fdat{story}, $fdat{headline}, $fdat{article} );
$http_headers_out{Location} = "edit_news.epl";
exit;
}
-]
<HEAD>
<TITLE>Edit Article</TITLE>
</HEAD>
<BODY BGCOLOR="white">
<H2>Edit Article</H2>
<HR>
<FORM METHOD="POST">
<P><B>Headline: </B><INPUT TYPE="text" NAME="headline" SIZE="50"></P>
<P><B>Article:</B> (HTML formatted)<BR>
<TEXTAREA NAME="article" COLS=60 ROWS=20></TEXTAREA></P>
<INPUT TYPE="reset" VALUE="Reset Form">
<INPUT TYPE="submit" NAME="save" VALUE="Save Article">
[$ hidden $]
</FORM>
<HR>
<P>Return to <A HREF="edit_news.epl">What's New Administration</A>.
<I>Warning, you will lose your changes!</I></P>
</BODY>
</HTML>The result looks like Figure 6-6.
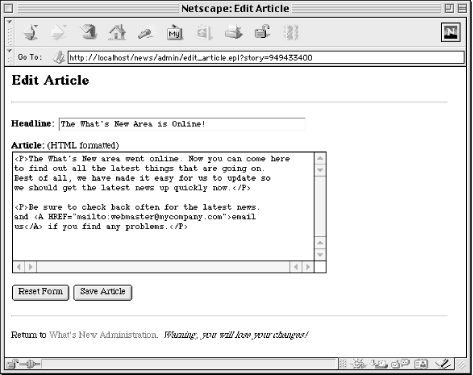
If the administrator is editing a page, then the story number will be supplied in the query string. We get this from %fdat and fetch the headline and article contents using get_story. We then set these fields in %fdat so that when Embperl encounters the headline and article form elements later in this file, it will pre-fill these defaults values for us automatically. The hidden command in the form below will be replaced with the story number if it was supplied. This is all we need to do in order to have the form handle new stories as well as edits.
When the administrator submits these changes, the story number (which will be present for edits and undefined for additions), the headline text, and the article text are supplied to the save_story function and the administrator is redirected back to the main administrative page.
The administrative functions from News are shown in Example 6-17.
sub save_story {
my( $story, $headline, $article ) = @_;
local *STORY;
$story ||= time; # name new files based on time in secs
$article =~ s/\015\012|\015|\012/\n/g; # make line endings consistent
$headline =~ tr/\015\012//d; # delete any line endings just in case
my( $file ) = $story =~ /^(\d+)$/ or die "Illegal filename: '$story'";
open STORY, "> $NEWS_DIR/$file";
flock STORY, LOCK_EX;
seek STORY, 0, 0;
print STORY $headline, "\n", $article;
close STORY;
}
sub delete_story {
my $story = shift;
my( $file ) = $story =~ /^(\d+)$/ or die "Illegal filename: '$story'";
unlink "$NEWS_DIR/$file" or die "Cannot remove story $NEWS_DIR/$file: $!";
}The save_story function takes an optional story file number, a headline, and article contents. If a number is not provided for the story, save_story assumes that this is a new story and generates a new number from date. We convert line endings from browsers on other platforms to the standard line ending for our web server and trim any line-ending characters from the headline because these would corrupt our data.
Again, we test the story number to make sure it is valid and then open this file and write to it, replacing any previous version if this is an update. We get an exclusive lock while we are writing so someone else does not try to read it before we finish (and get a partial news story). The delete_story function simply tests that the filename is valid and removes it.
As we have seen, Embperl presents a very different approach to generating dynamic output with Perl. We've covered what you need to know in order to develop most Embperl pages, but Embperl has many features and options that we simply do not have room to present. Fortunately, Embperl has extensive documentation, so if you want to learn more about HTML::Embperl, you can download it from CPAN and visit the Embperl website at http://perl.apache.org/embperl/.
|  | |
| 6.3. HTML::Template |  | 6.5. Mason |

Copyright © 2001 O'Reilly & Associates. All rights reserved.