 | CGI Programming with Perl |  |

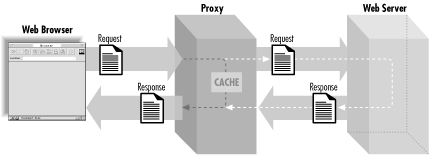
Quite often, web browsers do not interact directly with web servers; instead they communicate via a proxy. HTTP proxies are often used to reduce network traffic, allow access through firewalls, provide content filtering, etc. Proxies have their own functionality that is defined by the HTTP standard. We don't need to understand these details, but we do need to recognize how they affect the HTTP request and response cycle. You can think of a proxy as a combination of a simplified client and a server (see Figure 2-10). An HTTP client connects to a proxy with a request; in this way, it acts like a server. The proxy forwards the request to a web server and retrieves the appropriate response; in this way, it acts like a client. Finally, it fulfills its server role by returning the response to the client.
Figure 2-10 shows how an HTTP proxy affects the request and response cycle. Note that although there is only one proxy represented here, it's quite possible for a single HTTP transaction to pass through many proxies.
Proxies affect us in two ways. First, they make it impossible for web servers to reliably identify the browser. Second, proxies often cache content. When a client makes a request, proxies may return a previously cached response without contacting the target web server.
Basic HTTP requests do not contain any information that identifies the client. In a simple network transaction, this is generally not an issue, because a server knows which client is talking to it. We can see this by analogy. If someone walks up to you and hands you a note, you know who delivered the note regardless of what the note says. It's apparent from the context.
The problem is determining who wrote the note. If the note isn't signed, you may not know whether the person handing you the note wrote the note or is simply delivering it. The same is true in HTTP transactions. Web servers know which system is requesting information from them, but they don't know whether this client is a web browser that originated the request (i.e., the author of the note) or if they are just a proxy (i.e., the messenger). This is not a shortcoming of proxies, because this anonymity is actually a feature of proxies integrated into firewalls. Organizations with firewalls typically prefer that the outside world not know the addresses of systems behind their firewall.
Thus, unless the browser passes identifying information in its request to the server, there is no way to differentiate among different users on different systems since they could be connecting via the same proxy. We'll explore how to tackle this issue in Chapter 11, "Maintaining State".
One of the benefits of proxies is that they make HTTP transactions more efficient by sharing some of the work the web server typically does. Proxies accomplish this by caching requests and responses. When a proxy receives a request, it checks its cache for a similar, previous request. If it finds this, and if the response is not stale (out of date), then it returns this cached response to the client. The proxy determines whether a response is stale by looking at HTTP headers of the cached response, by sending a HEAD request to the target web server to retrieve new headers to compare against, and via its own algorithms. Regardless of how it determines this, if the proxy does not need to fetch a new, full response from the target web server, the proxy reduces the load on the server and reduces network traffic between the server and itself. This can also make the transaction much faster for the user.
Because most resources on the Internet are static HTML pages and images that do not often change, caching is very helpful. For dynamic content, however, caching can cause problems. CGI scripts allow us to generate dynamic content; a request to one CGI script can generate a variety of responses. Imagine a simple CGI script that returns the current time. The request for this CGI script looks the same each time it is called, but the response should be different each time. If a proxy caches the response from this CGI script and returns it for future requests, the user would get an old copy of the page with the wrong time.
Fortunately, there are ways to indicate that the response from a web server should not be cached. We'll explore this in the next chapter. HTTP 1.1 also added specific guidelines for proxies that solved a number of problems with earlier proxies. Most current proxies, even if they do not fully implement HTTP 1.1, have adopted these guidelines.
Caching is not unique to proxies. You probably know that browsers do their own caching too. Some web pages have instructions telling users to clear their web browser's cache if they are having problems receiving up-to-date information. Proxies present a challenge because users cannot clear the cache of intermediate proxies (they often may not even know they are using a proxy) as they can for their browser.
|  | |
| 2.4. Server Responses |  | 2.6. Content Negotiation |

Copyright © 2001 O'Reilly & Associates. All rights reserved.